| Tabla de Datos | ||||
| Información sobre diferentes conjuntos de datos | ||||
| Nombre | Tipo.de.red | Dataset | Bk.LB | Info |
|---|---|---|---|---|
| F1 | Completamente conectada | MNIST | 6,000 | Datos de escritura a mano |
| F2 | Completamente conectada | TIMIT | 72,133 | Conjunto estándar de grabaciones de habla para evaluar sistemas de reconocimiento automático, con 630 hablantes y transcripciones fonéticas. |
| C1 | Shallow Convolutional | CIFAR-10 | 5,000 | 60,000 imágenes en color de 10 clases diferentes para tareas de clasificación de imágenes. |
| C2 | Deep Convolutional | CIFAR-10 | 5,000 | 60,000 imágenes en color de 10 clases diferentes para tareas de clasificación de imágenes. |
| C3 | Shallow Convolutional | CIFAR-100 | 5,000 | 60,000 imágenes en color de 100 clases diferentes para tareas de clasificación de imágenes. |
| C4 | Deep Convolutional | CIFAR-100 | 5,000 | 60,000 imágenes en color de 100 clases diferentes para tareas de clasificación de imágenes. |
On large-batch training for deep learning: Generalization GAP and Sharp Minima
Introducción
En el proceso de entrenamiento de un modelo de aprendizaje nos enfrentamos al siguiente problema:
\[\min_{x} ~ f(x) := \frac{1}{M} \sum_{i = 1}^{M}{f_{i}(x)}\]
Donde \(f_{i}\) refiere a la función de perdida de la obseración i-ésima con \(i \in {1, 2, \cdots, M}\).
Como toda función de perdida, \(f_{i}\) captura la desviación de la predicción del modelo sobre los datos de entrenamiento.
Entrenamiento del modelo
El ajuste o entrenamiento del modelo se reudce a un problema de optimización (o se le parece). En particular, se busca encontrar el mínimo de la función \(f\).
Existen diferentes métodos para resolver este problema, la utilización de un algoritmo u otro y su convergencia depende de la naturaleza de la función \(f\).
- Convexidad
- Continiudad
- Derivabilidad
Entrenamiento del modelo (cont.)
Un método bastante utilizado es el método del gradiente estocástico (SGD) que consiste en un algoritmo recursivo para encontrar un mínimo local de una función diferenciable:
\[x_{k+1} = x_{k} - \alpha_{k} \left(\frac{1}{|B_{k}|} \sum_{i \in B_{k}}{\nabla}f_{i}(x_{k})\right)\]
Donde \(B_{k}\) es un subconjunto de los datos de entrenamiento y \(\alpha_{k}\) es el tamaño del paso en la iteración \(k\).
¿Qué tamaño de \(B_{k}\) es el mejor?
El objetivo general del articulo es medir cambios en la brecha (GAP) entre las métricas de training y test al considerar dos estrategias:
Large Batch (LB)
Small Batch (SB)
Con una estrategía de \(SB\) estamos considerando \(|B_{k}| << M\) donde valores comunes rondan entre \(32, 64, \cdots, 512\).
Contras de LB
- Métodos sobreajustan el modelo a los datos de entrenamiento.
- Métodos LB son atraidos por puntos de silla.
- LB pierden capacidad explorativa de los SB, tienden a estancarse en puntos críticos locales y no pueden escapar de ellos.
- LB y SB pueden converger a diferentes puntos críticos, el primero con puntos críticos de menor calidad.
Idea principal
- LB al tender a minimizadores bruscos (sharp) y esto afecta la generalización del modelo
- LB Minímos mas inestables
- LB Valores propios de la matriz Hessiana de \(f\) son mas grandes, lo que afectan la velocidad de convergencia y su alto valor nos indica una curvatura pronunciada en esa dirección.
¿Por qué LB y no SB?
Mas iteraciones para cubir la muestra de entrenamiento, al tener conjunto de datos pequeños es imposible paralelizarlo.
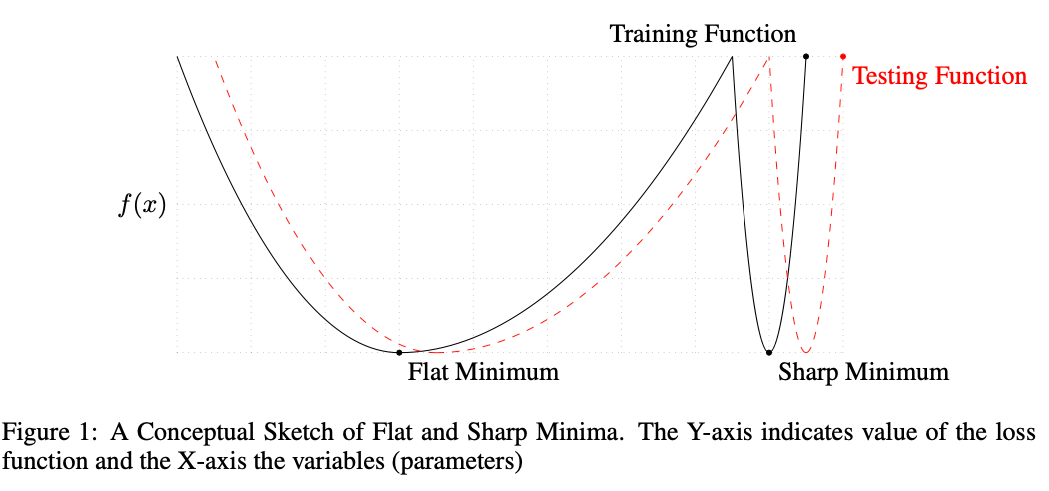
Puntos bruscos (sharp) o llanos (flat)
De forma gráfica, un punto brusco (sharp) es aquel que tiene una curvatura pronunciada en una dirección, mientras que un punto llano (flat) es aquel que tiene una curvatura suave en todas las direcciones.
Algoritmo ADAM
Inicializar θ₀, m₀, v₀ como 0
t ← 0
Mientras no se haya alcanzado el número máximo de iteraciones:
Obtener el conjunto de datos de entrenamiento X y sus etiquetas Y
Calcular el gradiente promedio:
gₜ = (1/|Bk|) ∑ᵢ ∇_θ 𝓛(θ_{t-1}, xᵢ, yᵢ)
Incrementar t: t ← t + 1
Actualizar los momentos:
mₜ = β₁ ⋅ m_{t-1} + (1 - β₁) ⋅ gₜ
vₜ = β₂ ⋅ v_{t-1} + (1 - β₂) ⋅ (gₜ ⊙ gₜ)
Corregir los momentos sesgados:
m̂ₜ = mₜ / (1 - β₁ᵗ)
v̂ₜ = vₜ / (1 - β₂ᵗ)
Actualizar los parámetros:
θₜ = θ_{t-1} - α ⋅ m̂ₜ / (√(v̂ₜ) + ε)Donde \(\epsilon = 0.001\) y \(\beta_{1} = 0.9\) ; \(\beta_{2} = 0.99\)
Experimentos
La estrategia SB, utilza un tamaño de lote de 256, para todos los conjuntos de datos.
Resultados
\[\text{(Precisión)} = \frac{\text{(TP)}}{\text{(TP)} + \text{(FP)}} \]
| Precisión | ||||
| Precisión de Entrenamiento (SB) y Test (LB) | ||||
| Name | Training (SB) | Training (LB) | Test (SB) | Test (LB) |
|---|---|---|---|---|
| F1 | 99.66% ± 0.05% | 99.92% ± 0.01% | 98.03% ± 0.07% | 97.81% ± 0.07% |
| F2 | 99.99% ± 0.03% | 98.35% ± 2.08% | 64.02% ± 0.2% | 59.45% ± 1.05% |
| C1 | 99.89% ± 0.02% | 99.66% ± 0.2% | 80.04% ± 0.12% | 77.26% ± 0.42% |
| C2 | 99.99% ± 0.04% | 99.99% ± 0.01% | 89.24% ± 0.12% | 87.26% ± 0.07% |
| C3 | 99.56% ± 0.44% | 99.88% ± 0.30% | 49.58% ± 0.39% | 46.45% ± 0.43% |
| C4 | 99.10% ± 1.23% | 99.57% ± 1.84% | 63.08% ± 0.5% | 57.81% ± 0.17% |
Representación paramétrica en una dimensión
Si tomamos \(x_{s}^{*}\) y \(x_{l}^{*}\) como los mínimos de \(f\) para \(SB\) y \(LB\) respectivamente podemos gráficar en un segmento que contenga a ambos puntos:
\[f(\alpha x_{s}^{*} + (1 - \alpha)x_{l}^{*})\]
Con \(\alpha \in [-1, 2]\).
En \(\alpha = 0\) tenemos el mínimo de \(LB\) y en \(\alpha = 1\) el mínimo de \(SB\).
Representación paramétrica en una dimensión (cont.)
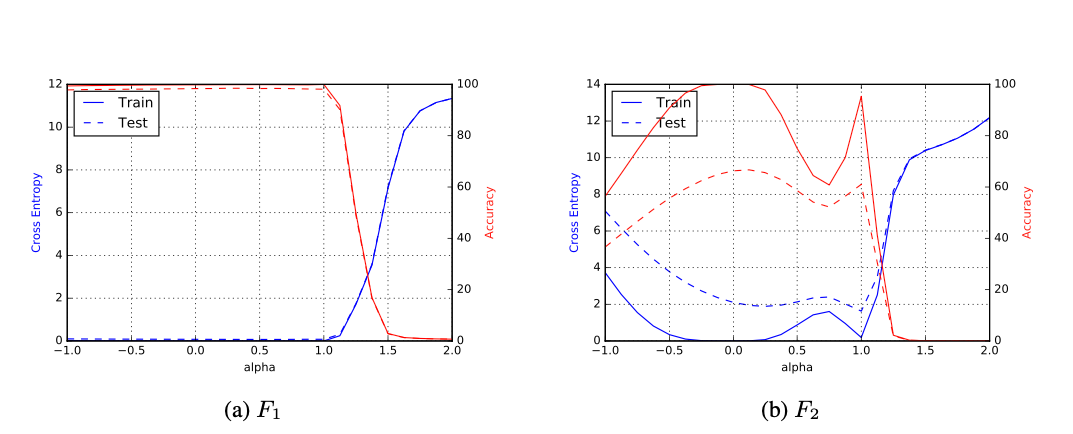
Representación paramétrica en una dimensión (cont.)
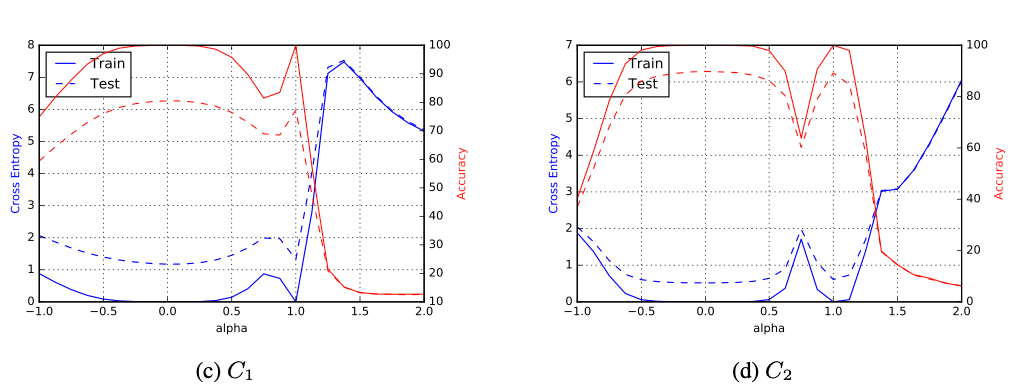
Representación paramétrica en una dimensión (cont.)
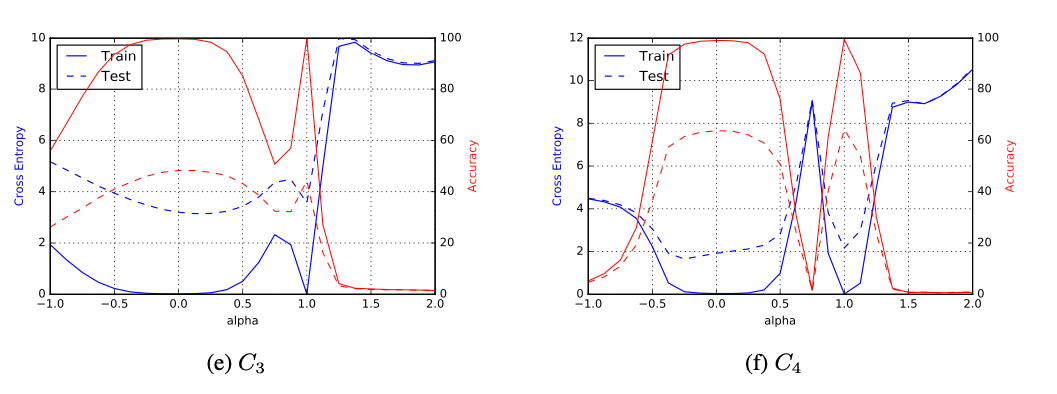
Representación paramétrica en una dimensión (cont.)
alpha_range = numpy.linspace(-1, 2, 25)
data_for_plotting = numpy.zeros((25, 4))
i = 0
for alpha in alpha_range:
for p in range(len(sb_solution)):
model.trainable_weights[p].set_value(lb_solution[p]*alpha +
sb_solution[p]*(1-alpha))
train_xent, train_acc = model.evaluate(X_train, Y_train,
batch_size=5000, verbose=0)
test_xent, test_acc = model.evaluate(X_test, Y_test,
batch_size=5000, verbose=0)
data_for_plotting[i, :] = [train_xent, train_acc, test_xent, test_acc]
i += 1Sharpness de los mínimos
La forma de los mínimos puede caracterizarse por los valores propios de la matriz Hessiana de \(f\) en el mínimo, en un contexto de optimización clásico mientras que en el ambito del aprendizaje tiene un alto costo computacional.
Al considerar un mínimo en una sola parte de \(R^{n}\), ver un conjunto del espacio total de tamaño \(p\) (variedades) para hacer esto se utiliza una matriz de \(n\) filas y \(p\) columnas generadas de forma aleatoria.
Sharpness de los mínimos (cont.)
Para asegurar la invarianza por la dimensionalidad y la dispersión se define un conjunto \(C_{\epsilon}\) como:
\[C_\varepsilon = \{ z \in \mathbb{R}^p : -\varepsilon (|(A+x)_i|+1) \leq z_i \leq \varepsilon (|(A+x)_i|+1)\}\] \[ \quad \forall i \in \{1,2,\dots,p\}\]
Donde \(A^{+}\) es la matriz pseudo-inversa de \(A\) y \(\varepsilon\) es un parámetro que controla el tamaño de la caja.
Sharpness de los mínimos (cont.)
\[\varphi_{x,f}(\varepsilon,A) := \frac{\left( \max_{y \in C_\varepsilon} f(x+Ay) \right) - f(x)}{1+f(x)} \times 100\]
Esta métrica se relaciona con el valor propio mas gránde de la matriz Hessiana de \(f\) en el mínimo y en el caso de considerar \(A\) se aproxima a los valores de \(Ritz\)
Sharpness de los mínimos (cont.)
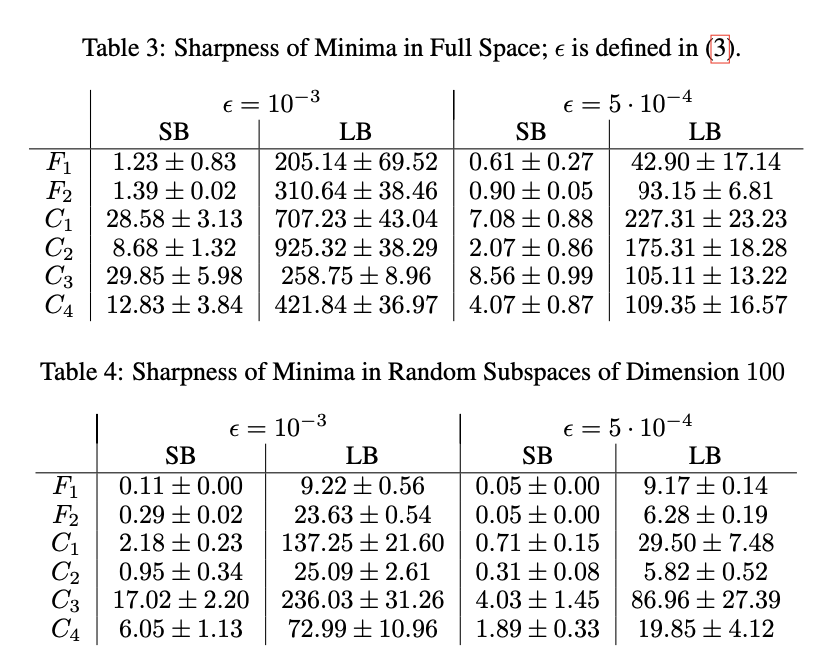
SB >> LB
- Comportamiento de SB (Small Batch) con gradientes ruidosos:
- Los gradientes ruidosos en métodos SB afectan el movimiento de las iteraciones. . . .
- El ruido en el gradiente aleja las iteraciones de los minimizadores afilados. . . .
- Promueve el movimiento hacia minimizadores más planos para evitar la influencia del ruido.
SB >> LB (cont.)
- Impacto del tamaño del lote:
- Cuando el tamaño del lote excede un umbral específico:
- El ruido en el gradiente estocástico no es suficiente para salir de la cuenca inicial. . . .
- Conduce a la convergencia hacia un tipo de minimizador más afilado.
- Cuando el tamaño del lote excede un umbral específico:
LB escapando del mínimo puntiagudo
Para mostrar como LB escapa de los mínimos se entreno una red en 100 iteraciones con un tamaño de lote de 256 (SB) y el resultado se utilizo como punto de partida para una estrategia LB.
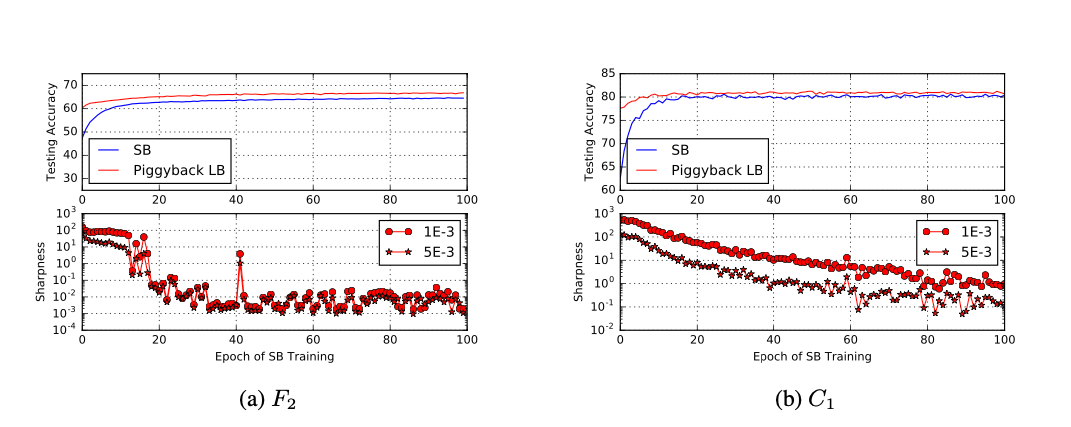
Preguntas abiertas
- ¿Los métodos de gran lote siempre convergen hacia minimizadores afilados en el aprendizaje profundo? . . .
- ¿Se pueden diseñar redes que funcionen mejor con métodos de gran lote?
- ¿Hay una manera de comenzar las redes para que los métodos de gran lote funcionen mejor? . . .
- ¿Podemos encontrar formas de evitar que los métodos de gran lote se enfoquen en minimizadores afilados?
Conclusiones
- La convergencia hacia minimizadores afilados afecta la capacidad de generalización en métodos de gran lote para el aprendizaje profundo. . . .
- Estrategias previas como la ampliación de datos y el entrenamiento conservador no resuelven completamente el problema de generalización deficiente en métodos de gran lote. . . .
- El muestreo dinámico muestra cierta promesa para mejorar los resultados de estos métodos. . . .
- La similitud en los valores de pérdida entre minimizadores afilados y planos es consistente con estudios previos.
Referencias
Goodfellow, Ian J., Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. Cambridge, MA, USA: MIT Press.
Goodfellow, Ian J., Oriol Vinyals, and Andrew M. Saxe. 2015. “Qualitatively Characterizing Neural Network Optimization Problems.” arXiv. https://doi.org/10.48550/arXiv.1412.6544.
Nitish Shirish Keskar, Jorge Nocedal, Dheevatsa Mudigere, and Ping Tak Peter Tang. 2016. “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima.” arXiv Preprint arXiv:1609.04836.